Technical Analysis
Challenge us to benchmark our engine against any of our competition

Innovative Solutions
ClipperDB pioneers cutting-edge technologies to revolutionize data management. Our team of experts is dedicated to delivering top-notch IT solutions tailored to your business needs. With a focus on innovation and efficiency, we strive to exceed expectations and drive success in the digital era.
Performance that changes the economics of Spark
ClipperDB replaces the Spark execution layer with a fully native engine, reducing query time and infrastructure cost without changing your pipelines.
ClipperDB accelerates Spark workloads by eliminating JVM overhead and running queries through dense native pipelines.
Cold start performance improves dramatically, with even greater gains as workloads warm.
2x Fastery Query Execution

Lower cost at the same scale
Because queries complete faster and resources are used more efficiently, clusters can be smaller while delivering the same or better performance.
The result is significantly lower cloud infrastructure spend for the same workload.
Half the Infrastructure Cost

Consistent performance across workloads
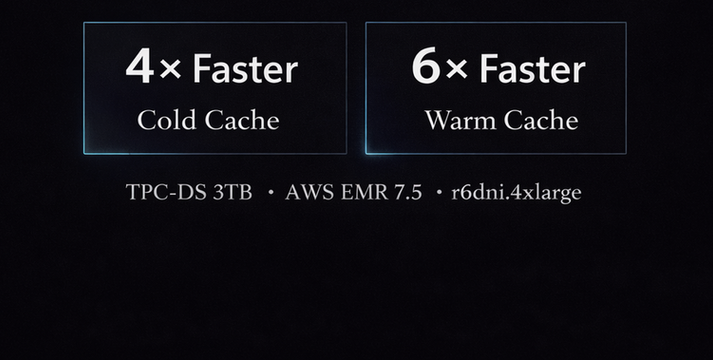
Native prefetch and in-memory column caching reduce execution stalls and minimize repeated cloud reads.
Performance improves as workloads warm, while cold-start latency is already significantly reduced.
Results based on TPC-DS workloads (3TB) on AWS EMR using identical clusters and query configurations.
Why ClipperDB is faster
ClipperDB executes Spark query plans using a fully native worker on each node.
No JVM execution overhead
No row/column conversion or memory copying
Streaming exchange between nodes
Local column chunk caching in DRAM